ECCV & IROS
These are some brief notes from ECCV and IROS, two of the biggest AI conferences, held in early and mid October 2024, in less than 2 weeks apart. I attended both, which was very satisfying and tiring. This pose summarizes some findings and impressions.
The State of Computer Vision
Milan is a nice city. I had already spent a lot of time there even before the conference, so my description here will be very brief. Last time I was there was about four years prior. In that time Milan seems to have grown well - it's becoming a modern, high-tech city. A unique feature is the all-you-can-eat sushi restaurants packed in the center. I'm only half-joking about this, they really do have great food. Anyway, it was nice to catch up on the latest political and tech issues with some fellow libertarian friends there.
ECCV was awesome - very high quality content and signal-to-noise ratio, lots of workshops, posters and talks. There is a lot that you can learn from attending one of these conferences. Its high status and popularity are merited. Altogether, 5 days of awesome computer vision topics, it was worth it. That being said, one of the big highlights was the "gala dinner" which was a proper party, and a big one at that. Two DJs, awesome music, industrial setting, very fun. I absolutely did not imagine a party of that kind was possible with that kind of target group.
Now, let's start with self-supervised learning. DINO [1] came out in 2021 and has already proved its utility. It is widely used. However, without supervision its attention heads attend to different parts of the image and it's hard to distinguish what are the objects. There are methods [2] that can do object localization with zero annotations by looking at the correlation between different patch features. A binary similarity graph is computed by simply looking at which patches have a positive cosine similarity. Then, objects are those patches which have the smallest degree. Other methods formulate a graph-cut problem [3], use spectral clustering [4] or otherwise manipulate these kinds of graphs based on feature similarity. It is also possible to detect the background by looking at the patches correlated to the one that receives the least attention [5].
Can we move from unsupervised localization to unsupervised segmentation? CLIP [37] offers the possibility for open-vocabulary segmentation but lacks spatial awareness. SSL methods usually have good spatial awareness without the need for labels. Hence, they can be combined. To extract dense semantic features from CLIP, one typically removes the last layer global attention pooling and replaces it with a \(1\times1\) convolution, producing \(N\) patch tokens of dimension \(d\). To do segmentation, you select a bunch of text classes, extract their embeddings, and compute the cosine similarity between each of them with each of the patch tokens, which is called MaskCLIP [6]. The resulting segmentation masks are noisy and there exist methods to improve them [7]. They work by averaging nearby CLIP features according to the similarity of the DINO patch features.
From the bigger models, there were EmuVideo [8], Cambrian-1 [9], VideoMamba [10], and Sapiens [11]. More and more works are exploring the problem of visual search. This is the problem of finding very small regions of interest in the image and answering questions about them. This is not an easy task. Suppose you are given a gigantic HD satellite image and I ask you about some small building. To find it, you'll likely have to iteratively zoom-in and zoom-out and otherwise make educated guesses. Naturally, this becomes a search task where you also need some form of working memory. A good paper here is \(V^*\) [12]. Similarly, searching for a specific scene in a long video requires making smart guesses about whether it occurs before or after the current frame.
Inspired by [13], there were also good papers that address various visual artifacts in DINO [14, 15]. Given the generality of these features, I find such works very useful. For autonomous vehicles, there were some good posters, including M\(^2\)Depth [16], which uses neighboring temporal frames to better estimate surrounding metric depth, RealGen [17], which stores encoded trajectories in a memory bank and uses retrieval-augmented generation to combine similar trajectories into new ones, and DriveLM [18], which uses a vision-language model for driving and question answering.
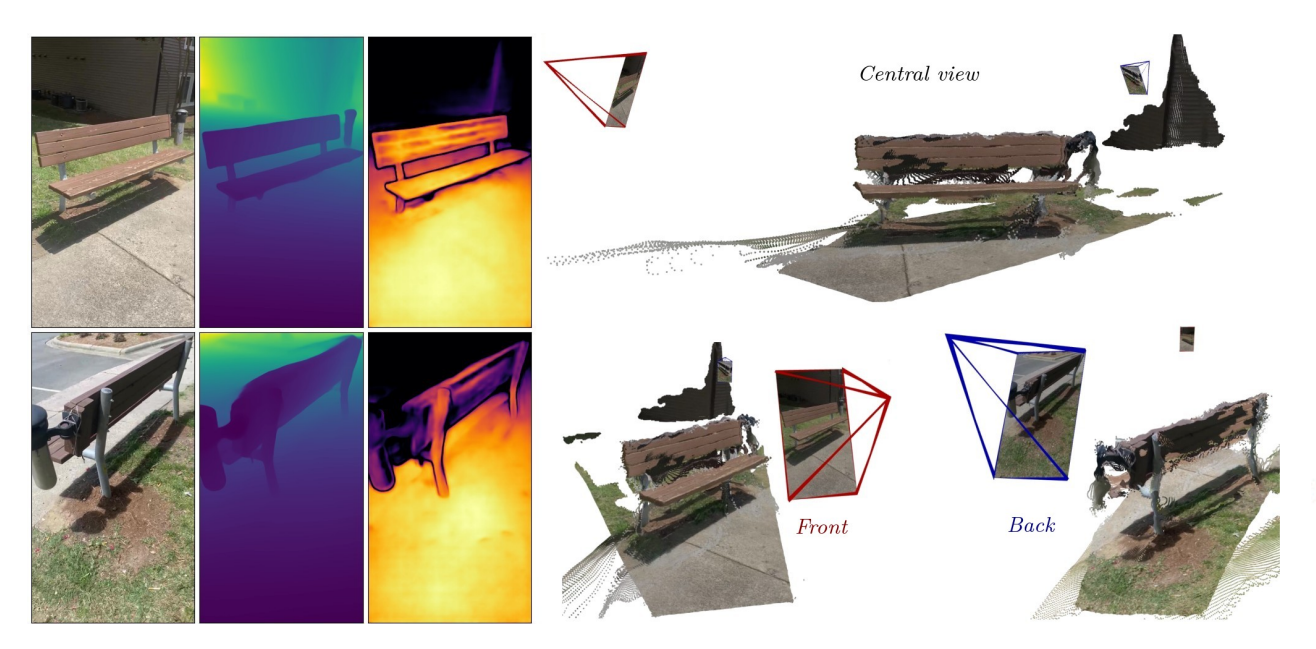
There were a lot of works on controllable diffusion along the lines of [19], Gaussian splatting, 6D pose estimation, synthetic avatars, radiance fields, and many others. [20] was an interesting twist on structure from motion, where they use scene coordinate networks (networks which directly predict the 3D location of a pixel). Also, I was quite amazed by the DUSt3R line of work [21, 22, 23]. The idea I'd say is quite beautiful - have a network that simply predicts the 3D location of every pixel. The inputs are two image views. They are encoded and decoded using transformers. The self-attention only attends over tokens in the same view. The cross-attention attends also over tokens from the other view. The outputs are two pointmaps in \(\mathbb{R}^{H \times W \times 3}\), in the coordinate frame of the first camera, which can be easily supervised. Given these pointmaps, it is easy to find correspondences, find intrinsic camera parameters, or estimate camera poses.
For point clouds, a good paper was PointLLM [24] which is relatively straightforward - a point cloud encoder extracts features and projects them to the space of tokens which are then processed by an LLM. On the more theoretical side there were interesting projects related to estimating shape from heat conduction [25], and rasterizing edge gradients in a novel way [26]. The latter is a major challenge in differentiable rendering and the usual way to do it is to use crude approximations to the discontinuous rasterization. I've explored this topic briefly here.
One very interesting paper is called Flying with Photons [27] and it renders transient videos of propagating light from novel viewpoints. To understand the task, consider a dark room and a light source that is suddenly turned on to illuminate the scene. If you have an ultra-high framerate camera you can capture a video of precisely how the room gets illuminated. You will see a pulse of light flying through the air. As the wavefront of this pulse hits surfaces, it reflects or scatters depending on the material properties of those surfaces. Each reflection event causes some of the light to change direction, sending it toward the camera and other parts of the scene. There are special cameras, called SPADs, that can capture billions of frames per second and can record the precise time when a photon lands on their sensors. Suppose ray \(\mathbf{r}\) is the ray through a single camera pixel. The camera typically divides the time into discrete bins and counts the number of photons within each time bin, suppose this count is \(\lambda_\mathbf{r}[n]\). Then, to create novel views a Nerf-like model is trained. Points on the ray \(\mathbf{r}\) are sampled, \(\mathbf{r}(s) = \mathbf{o} + s\mathbf{d}\), and for each one, a network predicts density \(\sigma(\mathbf{r}(s))\) and photon counts \(\mathbf{\tau}_\mathbf{r} \in \mathbb{R}_+^N\). Volumetric rendering is applied to produce an image, which is then supervised to the ground truth one. Each transient \(\mathbf{\tau}_\mathbf{r}\) is shifted in time to account for the time that it takes the light to go from \(\mathbf{r}(s)\) to the camera center \(\mathbf{o}\).

The Desert Sessions
Next up was IROS. We arrived in Doha, late in the evening, with a small delay, and barely cought our next flight to Abu Dhabz. The first moments in this new world were interesting. Locals, i.e. Arabs, are dressed in pristine white/black gowns and typically wear sandals and kanduras/hijabs. The nonlocals, usually immigrants, form the majority of the working-class and deal with menial tasks, manual labour and general work. When you go outside of the airport the hot wind hits you mercilessly in the face. Feels almost like Arizona, except that instead of cacti, there are palm trees. Unlike European cities, where you can get anywhere by walking or taking some public transportation, here the city is vast and less dense. The way to travel is by car. Luckily, Uber, an examplary product of capitalism, is available and is beyond convenient.
One particular nice sequence of events was after the first day of workshops and tutorials. Sunset was at 6 pm. Here's what I did. I totally recommend it. You Uber to the "Observation deck at 300", the highest vantage point in the city and look at the skyscrapers which have filled out the space northeast of you. The view is unique, you don't see lines or textures when it's dark, only individual shimmering golden points, like in a point cloud. Then walk to the Marina Mall where one can observe the lavish lifestyle of the locals. Then, walk to the end of the dock for a nice view of the downtown. Finally, walk all the way back to the Corniche beach. While you can't swim at night, you can walk along the shore. I can finally say I've dipped my feet into the Persian Gulf. The Corniche Street itself is amazing - wide, exotic, with palm trees and beach boardwalks on the side. Reminds me of Orchard Rd, Singapore. One can also explore Corniche from the north, which is similarly memorable. You literally walk for quite a long time, with the waves on your right, and the palm trees and skyscrapers on your left.
In terms of robotics, I'm impressed by how many practical exhibitions there were. All of them were amazing, owing to the fact that I'm new to the field. Some of the random things I saw:
- Biomimetic robots for swimming or flying. These include fish-like softrobots and bird-like robots that actually have a set of wings that they can flap.
- Aerial drone racing, this was quite impressive since the drones are fully-autonomous and fast. They fly in specifically designed cages (otherwise it's dangerous for the spectators) on a predefined route, marked by a number of square frames on which big QR code-like patterns are painted. The drone flyes by localizing these patterns and navigating through the frames. The goal is to go through the course as quickly as possible.
- Lots of bipeds, quadrupeds and other kinds of robots. These were typically remote controlled. I was amazed to see some of them be able to go up and down stairs and other slanted surfaces. In fact, there was a whole course devoted to quadrupeds moving in hazardous terrains.
- The first hanging of a robot. Just kidding, the robot was simply strapped across his neck, though it did resemble like he was hanging like a bag of sand in the air.
- Robo soccer players moving clumsily across the field and hitting the ball only to miss the gate. They even let a bunch of humanoid robots play soccer against a bunch of quadrupeds. This was a fun sight, a bunch of robots moving around a small playground with the surrounding people cheering them loudly. What's next? Robo boxing?
I find the robotics community quite down to earth, compared to the vision one. People explicitly state that their models and designs may not be always the best and usually avoid grandiose claims about solving this and that tasks. In general, current robotics is very far from being solved. People are only now starting to talk about robotic foundation models, even though generalist models like OpenVLA [28] or Octo [29] are still rudimentary and do not work in the wild.
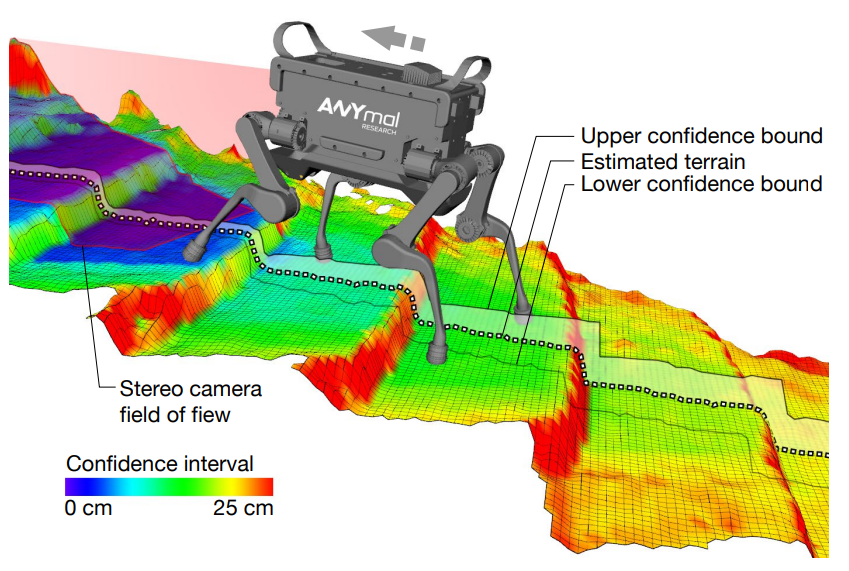
Robotics is a huge discipline and at IROS there were workshops and poster for literally any niche topic: multi-robot cooperation, path planning, mobile robots, maritime robotics, cybernetic avatars, manipulation, navigation, locomotion, all the different types of odometry, robotics for healthcare, biomimetics, haptics, drones, teleoperation, embodied intelligence, neuromorphic cameras, simultaneous localization and mapping, sensor design, terrain estimation, autonomous vehicles, control, simulation, soft robotics, biohybrid (cyborg) systems, and others.
A solid number of talks and presentations were about simultaneous localization and mapping (SLAM), the fundametal task of localizing the camera pose throughout a sequence of frames, and at the same time reconstructing the 3D scene captured by it. Starting from foundational works like iMap [31], we've come such a long way. Now there are SLAMs that use Nerfs [32] or GaussianSplats [33] for mapping, or that use RGB only instead of RGBD [34].
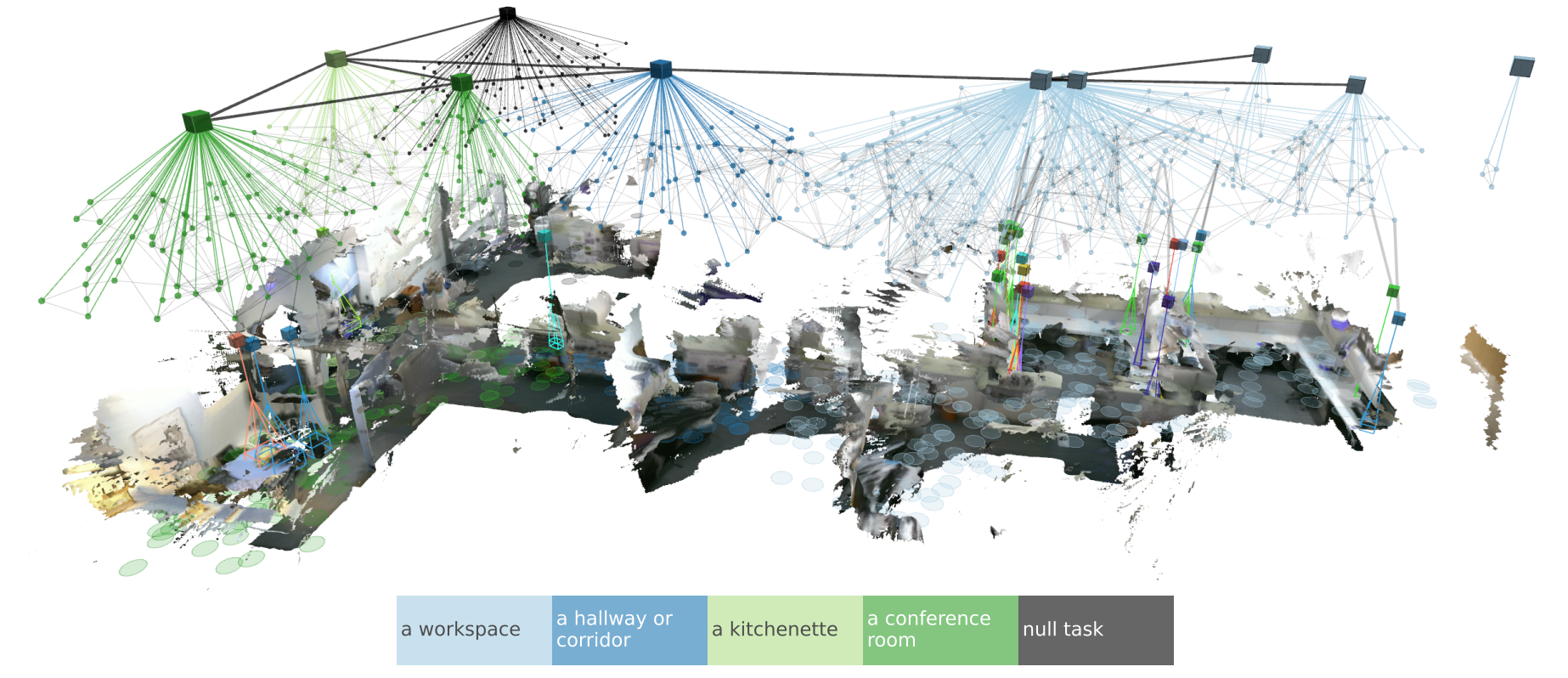
One of the most interesting ones, however, I think is Clio [35]. It tackles a fundamental problem in robotics - to create a useful map representation of the scene observed by the robot, where usefulness is measured by the ability of the robot to use the map to complete tasks of interest. This is important. Consider that with general class-agnostic segmentors like SAM [36] and open-set semantic embeddings like CLIP [37], we can now build maps with coutless semantic variations and objects. What is the right granularity for the representation? It is precisely that governed by the task. Robust perception relies on simultaneously understanding geometry, semantics, physics and relations in 3D. One approach to this is to build scene graphs. These are directed graphs where the nodes are spatial concepts and the edges are spatio-temporal relations. The key insight is that the scene graph needs to be hierarchical, owing to the fact that the environment can be described at different levels of abstraction. Which particular abstraction is utilized depends on the task.
Other notable activities during our stay there were eating camel burgers (tastes good, I recommend) and going to the Jubail mangrove park. We went there after sunset, yet managed to go through the boardwalks spanning a solid territory of mangrove forest. The ambience of this swamp is quite unique - you can hear the constant loud buzzing of crickets and cicada-like creatures. The water is relatively shallow and crystal clear, hence you can see the bottom and all the marine animals - mostly crabs and fish. Additionally, of all the things you can see there, we saw a rat, walking undisturbed along the boardwalks. Finally, lots of strange roots are sprouting up from the muddy ground. These are called pneumatophores, grow above the ground, and are common for mangrove-like plant habitats.
Another interesting location was the Sheikh Zayed Grand Mosque, the biggest in the country. Right next to it, we had the IROS gala dinner, a nice outdoor dinner in the courtyard of the ERTH hotel. Overall, a highly enjoyable and authentic experience and a great conclusion to IROS 2024.
References
[1] Caron, Mathilde, et al. Emerging properties in self-supervised vision transformers. Proceedings of the IEEE/CVF international conference on computer vision. 2021.
[2] Siméoni, Oriane, et al. Localizing objects with self-supervised transformers and no labels. arXiv preprint arXiv:2109.14279 (2021).
[3] Wang, Yangtao, et al. Tokencut: Segmenting objects in images and videos with self-supervised transformer and normalized cut. IEEE transactions on pattern analysis and machine intelligence (2023).
[4] Melas-Kyriazi, Luke, et al. Deep spectral methods: A surprisingly strong baseline for unsupervised semantic segmentation and localization. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
[5] Siméoni, Oriane, et al. Unsupervised object localization: Observing the background to discover objects. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023.
[6] Zhou, Chong, Chen Change Loy, and Bo Dai. Extract free dense labels from clip. European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2022.
[7] Wysoczańska, Monika, et al. Clip-dinoiser: Teaching clip a few dino tricks. arXiv preprint arXiv:2312.12359 (2023).
[8] Girdhar, Rohit, et al. Emu video: Factorizing text-to-video generation by explicit image conditioning. arXiv preprint arXiv:2311.10709 (2023).
[9] Tong, Shengbang, et al. Cambrian-1: A fully open, vision-centric exploration of multimodal llms. arXiv preprint arXiv:2406.16860 (2024).
[10] Li, Kunchang, et al. Videomamba: State space model for efficient video understanding. arXiv preprint arXiv:2403.06977 (2024).
[11] Khirodkar, Rawal, et al. Sapiens: Foundation for Human Vision Models. European Conference on Computer Vision. Springer, Cham, 2025.
[12] Wu, Penghao, and Saining Xie. V\(^*\): Guided Visual Search as a Core Mechanism in Multimodal LLMs. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024.
[13] Darcet, Timothée, et al. Vision transformers need registers. arXiv preprint arXiv:2309.16588 (2023).
[14] Yang, Jiawei, et al. Denoising vision transformers. arXiv preprint arXiv:2401.02957 (2024).
[15] Wang, Haoqi, Tong Zhang, and Mathieu Salzmann. SINDER: Repairing the Singular Defects of DINOv2. European Conference on Computer Vision. Springer, Cham, 2025.
[16] Zou, Yingshuang, et al. M\(^2\) Depth: Self-supervised Two-Frame Multi-camera Metric Depth Estimation. European Conference on Computer Vision. Springer, Cham, 2025.
[17] Ding, Wenhao, et al. Realgen: Retrieval augmented generation for controllable traffic scenarios. arXiv preprint arXiv:2312.13303 (2023).
[18] Sima, Chonghao, et al. Drivelm: Driving with graph visual question answering. arXiv preprint arXiv:2312.14150 (2023).
[19] Wang, Xudong, et al. Instancediffusion: Instance-level control for image generation. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024.
[20] Brachmann, Eric, et al. Scene Coordinate Reconstruction: Posing of Image Collections via Incremental Learning of a Relocalizer. arXiv preprint arXiv:2404.14351 (2024).
[21] Wang, Shuzhe, et al. Dust3r: Geometric 3d vision made easy. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024.
[22] Leroy, Vincent, Yohann Cabon, and Jérôme Revaud. Grounding Image Matching in 3D with MASt3R. arXiv preprint arXiv:2406.09756 (2024).
[23] Zhang, Junyi, et al. MonST3R: A Simple Approach for Estimating Geometry in the Presence of Motion. arXiv preprint arXiv:2410.03825 (2024).
[24] Xu, Runsen, et al. Pointllm: Empowering large language models to understand point clouds. arXiv preprint arXiv:2308.16911 (2023).
[25] Narayanan, Sriram, Mani Ramanagopal, Mark Sheinin, Aswin C. Sankaranarayanan, and Srinivasa G. Narasimhan. Shape from Heat Conduction. Computer Vision - ECCV 2024, Springer Nature Switzerland, 2025, pp. 426-444.
[26] Pidhorskyi, Stanislav, et al. Rasterized Edge Gradients: Handling Discontinuities Differentiably. arXiv preprint arXiv:2405.02508 (2024).
[27] Malik, Anagh, et al. Flying With Photons: Rendering Novel Views of Propagating Light. arXiv preprint arXiv:2404.06493 (2024).
[28] Kim, Moo Jin, et al. OpenVLA: An Open-Source Vision-Language-Action Model. arXiv preprint arXiv:2406.09246 (2024).
[29] Team, Octo Model, et al. Octo: An open-source generalist robot policy. arXiv preprint arXiv:2405.12213 (2024).
[30] Fankhauser, Péter, Michael Bloesch, and Marco Hutter. Probabilistic terrain mapping for mobile robots with uncertain localization. IEEE Robotics and Automation Letters 3.4 (2018): 3019-3026.
[31] Sucar, Edgar, et al. imap: Implicit mapping and positioning in real-time. Proceedings of the IEEE/CVF international conference on computer vision. 2021.
[32] Zhu, Zihan, et al. Nice-slam: Neural implicit scalable encoding for slam. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022.
[33] Matsuki, Hidenobu, et al. Gaussian splatting slam. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024.
[34] Zhu, Zihan, et al. Nicer-slam: Neural implicit scene encoding for rgb slam. 2024 International Conference on 3D Vision (3DV). IEEE, 2024.
[35] Maggio, Dominic, et al. Clio: Real-time Task-Driven Open-Set 3D Scene Graphs. arXiv preprint arXiv:2404.13696 (2024).
[36] Kirillov, Alexander, et al. Segment anything. Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023.
[37] Radford, Alec, et al. Learning transferable visual models from natural language supervision. International conference on machine learning. PMLR, 2021.